07 - Functional Dependencies and Normalization
(making sure the appropriate columns are in a table)
Objectives
- Deciding on a logical structure for a given body of data
- The concept of functional dependencies
- Determine the purpose of Normalization
- Problems associated with redundant data.
- Identification of anomalies
- Benifits of normalization
- Understand the process of normalization
- Identify 1st 2nd and 3rd normal form
Preamble
- Logical not physical design
- relational design (map to other models)
- an "art" not a science (some scientific priniples)
- data strucures and data integrity
- application-independent design (no matter what form, the design of the db is the same)
- deciding base relations and their attributes
Functional Dependencies (FD)
- A functional depenency is a relationship between two attributes.
- for any relation R, attribute B is functionally dependent on attribute A, if for every valid instance of A, that value of A uniquely determines the value of B

Examples---------------------------------
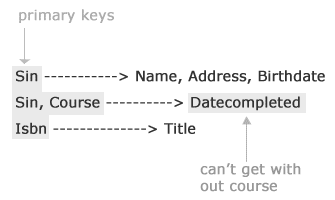
Functional Dependency Article
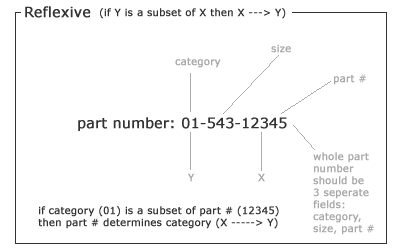


Examples
Given R(A,B,C,D) A --> B, B --> C
A-->BC | Union
A-->BCD | Cant tell. don't know what determines D
AD-->B | Augmentation (D is redundant only need A)
BC-->A | Cant tell. could be the same person + birth(?) not necessarily A
AB-->B | Reflexive
Note: I don't really understand this... it could be wrong as it doesn't make any sense to me.
Principle of Seperation
- Each tuple(row) of a relation contains an atomic, indivisible, unit of information.
- atomic: can't be broken down further
- indivisible: a distinct piece of information
Normalization
- reduce complex users' views to a set of small, stable, data structures (tables)
- normalized tables are flexible, stable, and easier to maintian
- reduces data redundance (procedes controlled data redundancy)
- eliminates data anomalies
Benefits of Data Normalization
- the development of a strategy for constructing relations and selecting keys.
- improved end-user computing activites (eg. accommodate ad-hoc queries, easier to create queries)
- reduced problems with adding, updating, and deleting data
- produces a hardware-independant, operating system system independent, DBMS independent and user-independent logical model
Anomalies
- anomalies occur when relations are not in the proper form
- insertion anomalies: attempting to insert a tuple with an unknown primary key
- deletion anomalies: deleting a tuple that contains important information
- update anomalies: occur when there is unnecessary redundancy in the data
Example
Problem: Making changes, adding/deleting/updating this table is going to be problematic.
 Add Tuple: {S85, 35, P1, 9}
Add Tuple: {S85, 35, P1, 9}Problem: Two tuples with conflicting budgets. (P1 can't be both the old 32 AND the new 35)
Delete Tuple: {S79,27,P3,1}
Problem: Deletes the budget of project P3.
Update Tuple: {S75, 32, P1, 7} to {S75, 35, P1, 7}
Problem: Two tuples with different values for project P1's budget.
Partial dependencies (redundancies) screw things up.
Solution: Normalize the table.
A: EMPID
B: BUDGET
C: PROJECT
D: HOURS
Given R(A,B,C,D) AC-->D, C-->B
AC-->BD = augmentation because C determines B, you don't need A,
however, you do need AC to determine hours.
AC-->D, C-->B = 3NF
empID, project --> budget, hours should be changed to:
empID, project --> hours;
project --> budget.

Note the following:
- No anomalies will be created if budget is changed
- No dummy values are needed for projects that have not employees assigned
- If an employee's contribution is deleted, no important data is lost
- No anomalies are created if an employee's contribution is added.
First Normal Form (1NF) - Repeating Groups Removed
Remove any multivalued attributes or repeating groups- In the first normal form only single values are permitted at the intersection of each row and column hence, there are no repeating groups
- To normalize a relation that contains a repeating group, remove the repeating group and form two new relations
- The primary key of the new relation is a combination of the primary key of the original relation plus an attribute from the newly created relation for unique identification. (The PK determines all attributes)
Example: An Unnormalized Table
Student_Grade_Report(#Studentno, student_name, major, course_no, course_name, instructor_no, instructor_name, instructor_location, grade)The course info is a repeating group. Take it out.
Student(#Studentno, student_name, major)
Student_Grade_Report(#Studentno, #course_no, course_name, instructor_no, instructor_name, instructor_location, grade)
Second Normal Form (2NF) - Partial Dependencies Removed
Q: Why upgrade to 2NF?A: We still have update anomalies in 1NF
To illustrate...
- In the above table to add a new course we sould need a student.
- When Course information needs to be updated, we may have inconsistencies
- In deleting a student, we may also delete critical information about a course
- The relation must first be in 1st normal form.
- The relation is automatically in 2NF if, and only if, the primary key comprises a single attribute.
- If the relation has a composite primary key, then each non-key attribute must be fully dependent on the entire primary key and not on a subset of the primary key (i.e. there must be not partial dependency).
Student(#Studentno, student_name, major)
Course_Grade(#Course_no, #Studentno, grade)
Course_Instructor(#Course_no, course_name, instructor_no, instructor_name, instructor_location, )
Third Normal Form (3NF) - Transitive Dependencies Removed
Q: Why upgrade from 2NF?
A:We still have update anomalies because of leftover transative dependencies.
To illustrate...
- When adding a new instructor, we need to have a course.
- Updating course information could lead to inconsistencies for instructor information.
- Deleting a course may also delete instructor information
- The Relation must be in 2nd normal form
- Remove all transative dependencies - a non-key attribute may not be functionally dependent on another non-key attribute.
Course_Grade(#student_no, #course_no, grade)
Course(#course_no, course_name, instructor_no)
Instructor(#instructor_no, instructor_name, instructor_location)
Now you should be anomaly free. You are good to update with out losing info, or creating inaccurate info.
posted by robott_rock @ 12:46 AM
![]()


0 Comments:
Post a Comment
<< Home